Vi invito a partecipare all’evento in cui sarò relatore insieme a Stefania Oliviero e che, con il gruppo GOSUB42, stiamo organizzando presso la Sala Consiliare del Comune di Gorgonzola il giorno 14 aprile 2023 alle ore 21:00.
immagine realizzata dalla collaborazione di ChatGPT con Midjourney
Immaginate un futuro in cui le macchine possano imparare, comprendere e risolvere problemi in modo simile agli esseri umani. Un futuro in cui l’intelligenza artificiale non sia soltanto un concetto astratto, ma un elemento fondamentale della nostra vita quotidiana, con un impatto positivo su salute, lavoro e svago.
Nel corso di questo evento, in modo divertente ed accessibile a tutti (anche ai non tecnici), ci proietteremo verso questo futuro esplorando alcune delle applicazioni più innovative dell’Intelligenza Artificiale tra cui: ChatGPT v4 e Midjorney. Siete tutti invitati!
La grafica di questa home page è stata rivista attraverso l’uso di Midjourney. Si tratta di un generatore di immagini che sfrutta un modello generativo basato su Intelligenza Artificiale. Dopo poche di ore di utilizzo ho ottenuto risultati straordinari. Le immagini di questo articolo sono state sintetizzate attraverso questo strumento.
immagine generata tramite Midjourneyimmagine generata tramite Midjourney
Incontriano ChatGPT 3 attraverso un’intervista esclusiva che ho realizzato per i lettori del magazine indipendente B-HOP. Il modello genativo, instancabile alchimista di parole e conoscenza, portato ai confini delle sue potenzialità, risponde brillantemente e con eleganza ad ogni domanda come mai nessuna macchina è stata in grado di fare nella storia dell’umanità. Le illustrazioni a corredo sono state realizzate tramite Deep Dream Generator.
Uno dei post che ha generato il maggior interesse in questo blog è certamente quello dedicato alla face detection tramite OpenCV. Riprendiamo questo tema dopo molto tempo parlando degli algoritmi alla frontiera per il Face Detection e Face Recognition. Lo scopo del post è fare il punto sullo stato dell’arte ed indirizzare verso mouduli open source liberamente e facilmente utilizzabili nelle applicazioni reali.
Matrix Reloaded – The Architect
La Face Detection è l’elaborazione che ha lo scopo di rilevare la presenza di volti umani all’interno di un’immagine digitale; nel precedente articolo è stata affrontata solo questa tematica attraverso algoritmi tradizionali ma consolidati.
Gli algoritmi di Face Detection si sono evoluti nel tempo migliorando l’accuratezza della rilevazione anche attraverso l’uso di reti neurali convoluzionarie (CNN)o reti Deep Learning opportunamente strutturate ed addestrate; tale processamento sfrutta massivamente l’eventuale presenza di moderne GPU o NPU per aumentarne l’efficienza ed il parallelismo. Nel nostro caso specifico ci siamo limitati al riconoscimento di volti umani in posizione frontale.
Matrix Reloaded Architect – Face Detection Benchmark MTCNN
Il benchmark estremo che ho utilizzato per mettere alla prova i moduli python individuati, è un breve video tratto dal dialogo tra Neo e l’Architetto in Matrix Reloaded; nel video, in un’atmosfera surreale, sono presenti innumerevoli volti che variano rapidamente per dimensione, inclinazione, espressione, presenza o meno di occhiali. Un video estremo di prova che farà friggere neuroni e sinapsi anche alle più evolute e performanti reti neurali convoluzionarie.
Questo è il video che è stato prodotto attraverso la nostra elaborazione:
Il Benchmark che ho utilizzato per la Face Detection in Python – L’architetto in Matrix Reloaded – questo è il risultato ottenuto tramite l’uso del modulo MTCNN insieme ad OpenCV che ho usato per l’elaborazione del video
Il modulo Python che, almeno nei miei esperimenti, ha dimostrato i migliori risultati in termini di qualità e prestazioni è MTCNN; in esecuzione su una sessione Colab con GPU attiva elabora efficientemente il flusso di frame con un livello di accuratezza molto alto se si escludono i volti in posizione non frontale. Nel video prodotto si trova l’esito dell’elaborazione dove, oltre ai volti, sono stati marcati anche alcuni punti caratteristici del viso (occhi, naso, estremi della bocca). Questo modulo è quello che riesce a rilevare meglio volti di dimensioni più piccole e non perfettamente allineati garantendo anche un’efficienza molto più alta degli altri moduli provati; MTCNN fornisce, per ogni volto rilevato, anche un livello di confidenza nella rilevazione (in tutto il video ho trovato solo un falso positivo pertanto non ho ritenuto necessario introdurre una soglia).
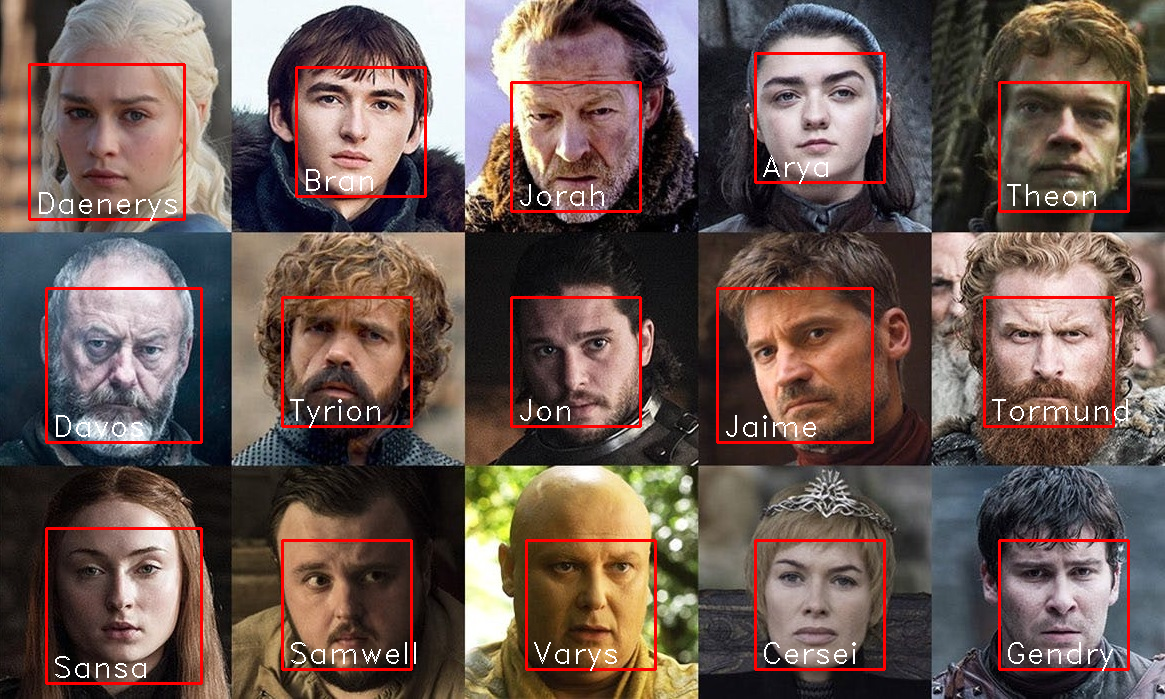
Il Trono di Spade – foto usata come base per l’apprendimento dei principali personaggi
In alternativa, si propone l’uso del modulo: face_recognition che ha comunque garantito un’ottima precisione su volti di dimensioni significative ed un’efficienza adeguata; su tale modulo è possibile variare l’algoritmo di rilevamento (CNN o HOG) ed effettuare del tuning per cercare di rilevare volti di dimensioni minori. Sul benchmark utilizzato la rilevazione CNN non riusciva ad intercettare gli stessi volti di MTCNN mentre la rilevazione HOG, oltre a non velocizzare molto il processamento, riduceva drasticamente il numero di volti rilevati. In condizioni normali anche questo modulo è da considerare un’ottima scelta e noi lo useremo per effettuare anche il Face Recognition. Questo modulo può richiedere un quantitativo di memoria sulla GPU più elevato soprattutto se si vogliono rilevare i volti con dimensioni più piccole.
Tutti i personaggi sono stati correttamente rilevati
Dopo aver rilevato ed isolato i volti, l’elaborazione della Face Recognition ci permette l’associazione di un volto ad una persona. In assenza di informazioni o di preappendimento sulle persone da ricercare, è possibile aggregare i volti su possibili individui basandosi sulla similitudine delle caratteristiche fisiologiche e biometriche. Gli algoritmi per effettuare tale riconoscimento, per codificare un volto in un insieme di parametri comparabili sono davvero molteplici e tutti estremamente interessanti. Anche in questo caso le reti neurali convoluzionarie (CNN) offrono un contributo importante a questi algoritmi.
Tutti i personaggi sono stati correttamente rilevati ad eccezione di Missandei che non era presente nella foto iniziale
Per implementare un Face Recognition in pochissime righe di codice Python ed in modo efficiente è possibile usare il modulo face_recognition; se si vuole approfondire come questo modulo funziona internamente vi consiglio di leggere questo aricolo.
Tutti gli attori presenti nel file di training sono stati correttamente rilevati anche senza abiti ed acconciature di scena. Come atteso Drogo non viene rilevato perché non presente nel file di training.
In questo caso ho creato un notepad colab di test che da una foto iniziale acquisisce le caratteristiche fisiologiche e biometriche dei vari personaggi della serie Il Trono di Spade; il modulo utilizzato, alla versione attuale, dovrebbe rappresentare ciascun volto tramite 128 parametri caratteristici.
tutti gli attori presenti nella foto di training sono stati rilevati anche Daenarys che appare molto differente rispetto al personaggio interpretato
Per testare il rilevamento ho provato a far riconoscere i personaggi su altre foto contenenti anche personaggi non presenti all’interno della foto di apprendimento; i risultati sono impeccabili. Il modulo utilizzato ha un’accuratezza eccellente sia per quanto riguarda i personaggi appresi che per quelli non analizzati che non ha mai classificato come falsi positivi.
anche in questo caso tutti gli attori presenti nella foto di training sono stati individuati correttamente
Per spingere oltre il test abbiamo avviato la detection su foto in cui gli attori non appaiono con i costumi di scena ed hanno acconciature o il colore dei capelli totalmente differente dai personaggi che hanno interpretato; anche in questo caso l’algoritmo non sbaglia e non rileva mai falsi positivi.
Anche se non ho effettuato delle prove dirette, sono convinto che l’algoritmo scali bene all’aumentare del numero delle persone da rilevare; non ho provato a sottoporre qualche foto degli attori quando erano più giovani.
Concludiamo dicendo che oltre alla Face Detection ed alla Face Recognition ai volti possono essere applicati altri algoritmi per l’estrazione di caratteristiche molto importanti come la rilevazione del sesso, dell’età, del sentimento (es. rabbia, gioia, paura, sorpresa, …).
Fatemi sapere i vostri pareri e le vostre esperienze su Face Detection, Face Recognition nei commenti.
L’RMS Titanic è stato un transatlantico britannico della classe Olympic naufragato nelle prime ore del tragico 15 aprile 1912, durante il suo viaggio inaugurale, a causa della collisione con un iceberg avvenuta nella notte.
La sfida proposta da Kaggle: Titanic – Machine Learning from Disaster alla quale ho aderito, richiede l’analisi di un dataset contenente informazioni relative ad un sottoinsieme di passeggeri imbarcati sul Titanic con lo scopo di realizzare un modello predittivo che sia in grado di classificare al meglio se un determinato passeggero si salverà dal naufragio.
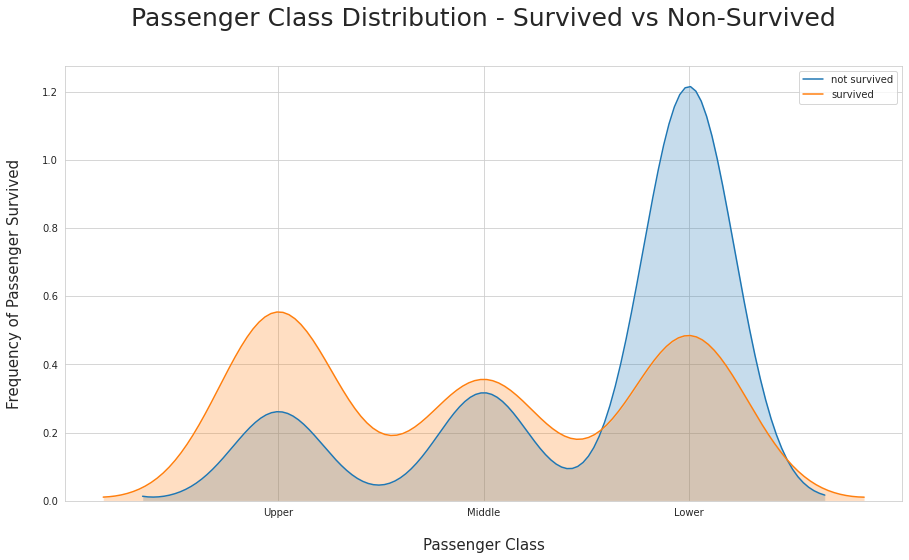
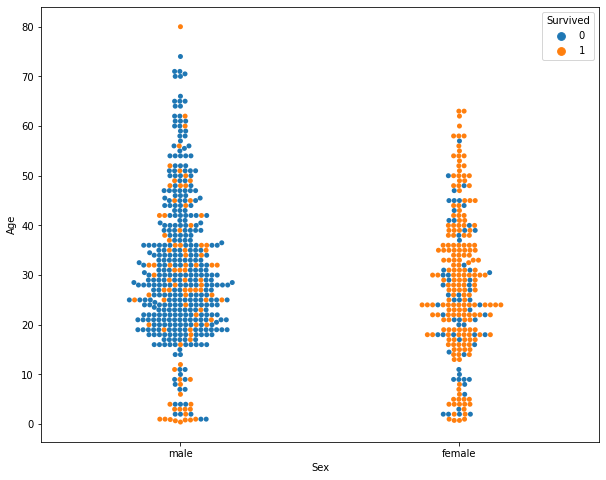
tassi di sopravvivenza per classe
Alcune delle informazioni disponibili per l’analisi, di cui occorre individuare il livello di correlazione con la probabilità di salvezza, sono: sesso, età, cabina, classe, ponte, numero di parenti a bordo, porto di imbarco, tariffa pagata; moltissime altre informazioni possono essere derivate da elaborazioni più o meno complesse ed implicite tra i dati disponibili come ad esempio dai nomi completi è possibile risalire ai titoli, ad alcune professioni o anche spingersi al raggruppamento delle famiglie.
La grande sfida è quella di spingere al massimo l’accuratezza del modello predittivo al fine di classificare al meglio un insieme di passeggeri di test di cui non è nota la sorte; solo dopo la sottomissione a Kaggle si scoprirà il livello di accuratezza raggiunto.
Il modello predittivo di base che occorre superare e contro il quale ci si deve confrontare, che ho definito come modello baseline, assume semplicemente che tutte le donne si salveranno; applicando questa condizione elementare, si raggiunge un’accuratezza dell’insieme di passeggeri da classificare di poco superiore al 76%.
modello baseline: tutte le donne si salvano raggiunge un’accuratezza dello 0.76555
Questa competizione è un’ottima introduzione alla piattaforma Kaggle e richiede lo sviluppo di tutte le fasi di costruzione di un modello predittivo: analisi dei dati, preparazione e raffinamento dei dati, visualizzazione dei dati, costruzione del modello, validazione del modello e della sua accuratezza, comprensione della piattaforma Kaggle.
Nel mio notebook ho deciso di affrontare la sfida in Python costruendo un modello tramite la libreria XGBoost nota sia per essere alla base delle migliori implementazioni all’avanguardia del settore ma anche perché alla base dei modelli vincenti delle competizioni Kaggle. Tale libreria implementa il framework Gradient Boostin modalità estremamente scalabile, efficiente e portabile.
La mia implementazione, già completamente funzionante, è ancora in evoluzione è raggiungibile a questo indirizzo:
Al fine di comprendere meglio l’articolo: “Modeling How Infectious Diseases like Coronavirus Spread“ ed i riferimenti citati, continuando ad approfondire, mi sono ritrovato a costruire il framework: “Infection Spread Simulator Construction Kit”.
Si tratta di un notebook Python su Colab per la modellazione della diffusione di un’infezione attraverso un modello SEIR descritto da un sistema di equazioni differenziali (o un algoritmo); lo stesso modello proposto per l’analisi della diffusione del covid-19 nell’articolo che ha ispirato questo lavoro.
Chiunque, anche senza nessuna base matematica, con una conoscenza basilare di programmazione, può modificare il notebook all’interno della propria sandbox Colab, descrivere un virus o il comportamento di un’infezione ed analizzare la sua diffusione nel tempo per comprendere come la variazione di certi parametri può incidere nella diffusione.
Si tratta di un prototipo, nato per uso strettamente personale, con molti limiti ma voglio comunque condividerlo con la comunità rilasciandolo come software libero sotto la licenza GNU/GPL v.3.
Sarei felice di ricevere i vostri feedback, i vostri modelli, le vostre evoluzioni anche direttamente su github. Nei prossimi giorni, utilizzando questo framework o una sua evoluzione, vorrei provare a realizzare il complesso modello di diffusione del covid-19 descritto nell’articolo.
MALARIA Il primo modello reale (estensione del SEIR) che rilascio è quello della malaria. In questo caso ho dovuto apportare delle modifiche più complesse al modello base.
Some years ago, needing to quickly identify duplicate files within Unix file systems residing on embedded devices or NAS (e.g., Synology, QNAP, D-Link), and dissatisfied with the tools I found online, I developed a command-line Perl tool with the following goals:
Very lightweight and usable even on embedded devices (requires only the Perl 5.7.3 interpreter or higher, with no additional dependencies);
Maximum efficiency on very slow disks or network drives.
Thus, the first version of the free software ffdup was born, which I released under the GNU/GPL v3.0 license on:
Mi affaccio alla finestra dopo una lunga domenica. E’ una notte gelida d’inverno: Gorgonzola, imbiancata tutto il giorno dalla neve, s’addormenta lentamente, le luci dei palazzi vicini sono ormai spente. Non ho sonno!
I seggi elettorali sono chiusi da alcune ore: gli italiani hanno dovuto esprimere i propri voti per il rinnovo del Parlamento. Nel segreto delle urne è celato parte del futuro del nostro paese; rifletto su quanto sia complesso il modello sociale del voto.
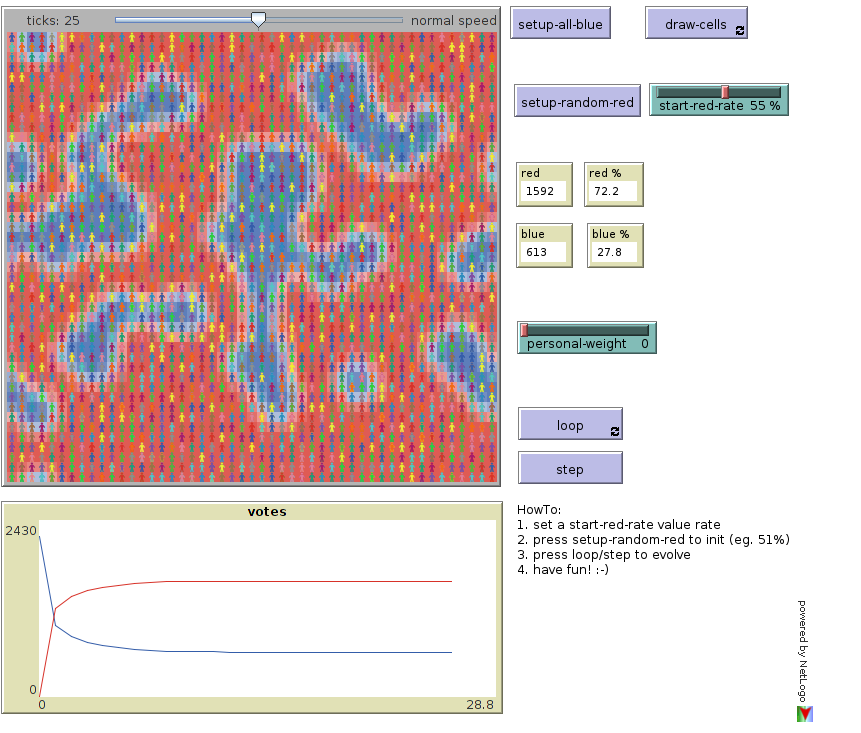
Mi addormento proponendovi un automa cellulare che simula la regola “Gérard Vichniac voting” o “Majority” in cui, ogni cella dell’automa cellulare bidimensionale, assume lo stato della maggioranza delle otto celle limitrofe.
Definita una configurazione iniziale, dopo una breve evoluzione, il sistema si stabilizza facendo emergere surrealistiche forme simili a continenti.
Nella figura, generata dal simulatore, il colore è funzione dell’orientamento politico (rosso, blu) e convinzione dell’elettore (chiaro, scuro).
Per realizzare la simulazione ho utilizzato NetLogo: un ambiente di simulazione per modelli basati su agenti. Si tratta di un software libero multi-piattaforma.
Per esplorare le potenzialità di questo ambiente, vi consiglio di provare i modelli presenti nella: NetLogo Models Library.
Il mio automa cellulare è disponibile online in questa pagina (si tratta di un’applet Java esportata da NetLogo).
Per iniziare, si consiglia di: impostare un livello di rossi “start-red-rate” es. 51%, cliccate su “setup-random-red” per inizializzare le celle e poi cliccate su “loop” per analizzare l’evoluzione del voto nel tempo fino alla stabilizzazione.
E’ impostabile anche il “personal-weight” ovvero il livello di convinzione dell’elettore (valori consigliati: 0, 1, 2); più è alto tale valore più difficilmente l’elettore si farà influenzare dai suoi otto vicini.
E’ da molto che non scrivo in questo blog; semplicemente sono stato impegnato in alcuni progetti che non reputo ancora pubblicabili.
Voglio segnalarvi due interessanti riferimenti nel campo dell’AI, computational intelligence, machine learning; argomenti di cui mi sto occupando in questo periodo.
The Pac-Man Projects
Come base degli esercizi per un corso di intelligenza artificiale, presso l’università di Berkeley, viene proposto agli studenti di sviluppare in python alcuni algoritmi all’interno del famoso gioco del Pac-Man; il corso termina con un multi-player contest.
Trovo questa idea geniale e molto efficace dal punto di vista didattico.
Il materiale può essere liberamente utilizzato come base per corsi di intelligenza artificiale ma si richiede di non pubblicare online le soluzioni dei problemi posti.
Ms Pac-Man vs Ghost Team Competition
Per chi volesse cimentarsi nello sviluppo in java di algoritmi che pilotano Ms Pac-Man o la squadra dei quattro fantasmi è stata organizzata un’avvincente competizione:
Per festeggiare degnamente l’arrivo del mio nuovo portatile in famiglia ho pensato di renderlo in grado di riconoscere volti umani da una sorgente video in tempo reale.
Video dell’applicazione realizzata
Segue il video dimostrativo dell’applicazione realizzata:
OpenCV (Open Source Computer Vision Library)
Era da tempo che desideravo utilizzare la libreria Open CV per tornare a fare qualche esperimento di Computer Vision e per esplorare le sue tanto decantate potenzialità.
OpenCV è una libreria rilasciata sotto licenza BSD dalla Intel per l’elaborazione realtime delle immagini e la Computer Vision.
Scritta in C e C++ è utilizzabile, tramite wrapper (sia ufficiali che non) in diversi linguaggi: Python, Ruby, Java, C# ed è stata portata sui principali sistemi operativi: GNU/Linux, FreeBSD, Mac OS X, Windows ma anche Android e iOS per lo sviluppo di applicazioni su dispositivi mobili.
Alcuni wrapper esportano solo un limitato sottoinsieme di funzionalità.
Mi sono reso conto che le potenzialità di tale libreria sono superiori alle mie più rosee aspettative: c’è tutto quello che può servire (e si può sognare) per realizzare applicazioni avanzate di Computer Vision ed elaborazione delle immagini.
Sviluppare un’applicazione di ottima qualità per la face detection in realtime, problema normalmente complesso, diventa banale a tal punto che mi sono limitato a fare qualche ricerca su internet ed assemblare poche righe di codice Python trovate in alcuni blog.
Face Detection ed Haar-like features
L’algoritmo molto efficiente che viene utilizzato per la rilevazione dei volti, basato sulle Haar wavelet, è stato elaborato da Viola-Jones nell’ambito dell’object detection ed è stato pensato proprio per il problema della face detection in tempo reale.
Con OpenCV è possibile addestrare nuovi identificatori di oggetti tuttavia sono già presenti i seguenti classificatori (in formato xml):
Nelle mie prove, dopo aver individuato il volto, ho provato a rilevare anche gli occhi e la bocca ma in questo caso i risultati non mi hanno soddisfatto.
Sorgente Python
I miei esperimenti sono stati effettuati su una macchina GNU/Linux Ubuntu 11.04 con OpenCV 2.1.
E’ richiesto il pacchetto python-opencv, presente nei repository ufficiali e si assume che nel path dello script sia presente una directory haarcascades contenente i vari xml necessari per la detection.
Su Ubuntu 11.04 è possibile trovarli nella directory:
segue il codice sorgente utilizzato per la realizzazione del video:
#!/usr/bin/python
#----------------------------------------------------------------------------
# Face Detection Test (OpenCV)
#
# thanks to:
# http://japskua.wordpress.com/2010/08/04/detecting-eyes-with-python-opencv
#----------------------------------------------------------------------------
import cv
import time
import Image
def DetectFace(image, faceCascade):
min_size = (20,20)
image_scale = 2
haar_scale = 1.1
min_neighbors = 3
haar_flags = 0
# Allocate the temporary images
grayscale = cv.CreateImage((image.width, image.height), 8, 1)
smallImage = cv.CreateImage(
(
cv.Round(image.width / image_scale),
cv.Round(image.height / image_scale)
), 8 ,1)
# Convert color input image to grayscale
cv.CvtColor(image, grayscale, cv.CV_BGR2GRAY)
# Scale input image for faster processing
cv.Resize(grayscale, smallImage, cv.CV_INTER_LINEAR)
# Equalize the histogram
cv.EqualizeHist(smallImage, smallImage)
# Detect the faces
faces = cv.HaarDetectObjects(
smallImage, faceCascade, cv.CreateMemStorage(0),
haar_scale, min_neighbors, haar_flags, min_size
)
# If faces are found
if faces:
for ((x, y, w, h), n) in faces:
# the input to cv.HaarDetectObjects was resized, so scale the
# bounding box of each face and convert it to two CvPoints
pt1 = (int(x * image_scale), int(y * image_scale))
pt2 = (int((x + w) * image_scale), int((y + h) * image_scale))
cv.Rectangle(image, pt1, pt2, cv.RGB(255, 0, 0), 5, 8, 0)
return image
#----------
# M A I N
#----------
capture = cv.CaptureFromCAM(0)
#capture = cv.CaptureFromFile("test.avi")
#faceCascade = cv.Load("haarcascades/haarcascade_frontalface_default.xml")
#faceCascade = cv.Load("haarcascades/haarcascade_frontalface_alt2.xml")
faceCascade = cv.Load("haarcascades/haarcascade_frontalface_alt.xml")
#faceCascade = cv.Load("haarcascades/haarcascade_frontalface_alt_tree.xml")
while (cv.WaitKey(15)==-1):
img = cv.QueryFrame(capture)
image = DetectFace(img, faceCascade)
cv.ShowImage("face detection test", image)
cv.ReleaseCapture(capture)
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.



















}{\partial t} = -\lambda s(t)i(t) \\ \dfrac{\partial e(t)}{\partial t} = \lambda s(t)i(t) - \dfrac{e(t)}{\xi} \\ \dfrac{\partial i(t)}{\partial t} = \dfrac{h}{\xi} e(t) - \dfrac{i(t)}{\mu} \\ \dfrac{\partial r(t)}{\partial t} = \dfrac{h}{\mu} i(t) \end{cases}")