
L’RMS Titanic è stato un transatlantico britannico della classe Olympic naufragato nelle prime ore del tragico 15 aprile 1912, durante il suo viaggio inaugurale, a causa della collisione con un iceberg avvenuta nella notte.

La sfida proposta da Kaggle: Titanic – Machine Learning from Disaster alla quale ho aderito, richiede l’analisi di un dataset contenente informazioni relative ad un sottoinsieme di passeggeri imbarcati sul Titanic con lo scopo di realizzare un modello predittivo che sia in grado di classificare al meglio se un determinato passeggero si salverà dal naufragio.
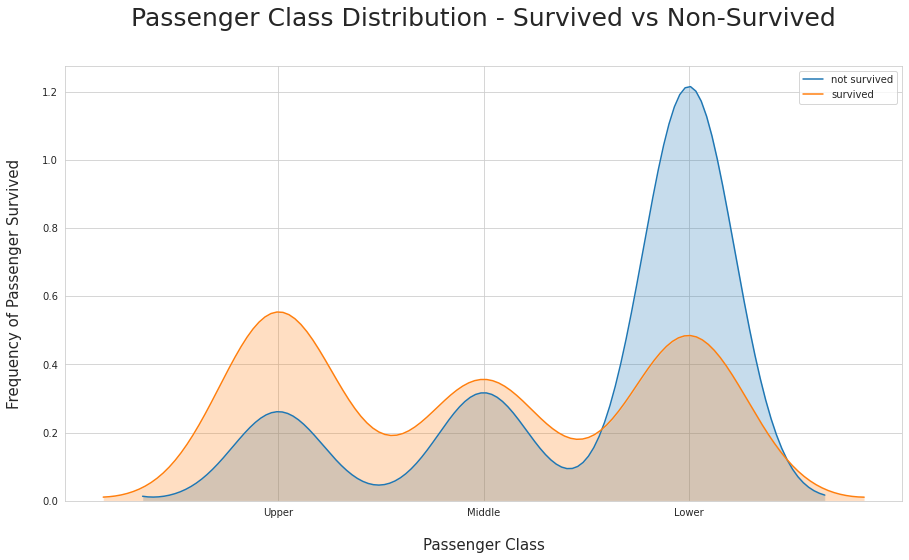
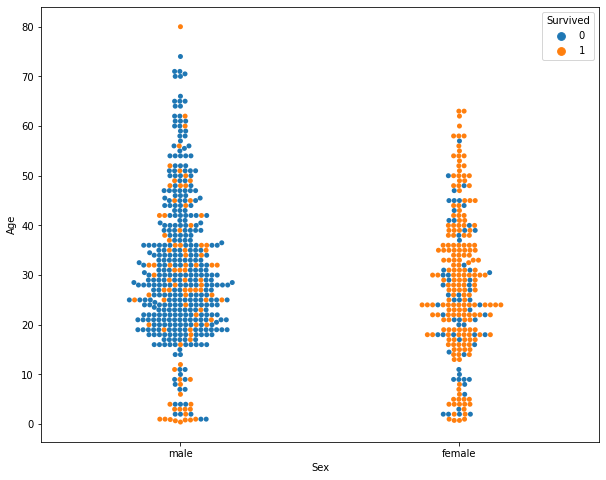
Alcune delle informazioni disponibili per l’analisi, di cui occorre individuare il livello di correlazione con la probabilità di salvezza, sono: sesso, età, cabina, classe, ponte, numero di parenti a bordo, porto di imbarco, tariffa pagata; moltissime altre informazioni possono essere derivate da elaborazioni più o meno complesse ed implicite tra i dati disponibili come ad esempio dai nomi completi è possibile risalire ai titoli, ad alcune professioni o anche spingersi al raggruppamento delle famiglie.
La grande sfida è quella di spingere al massimo l’accuratezza del modello predittivo al fine di classificare al meglio un insieme di passeggeri di test di cui non è nota la sorte; solo dopo la sottomissione a Kaggle si scoprirà il livello di accuratezza raggiunto.
Il modello predittivo di base che occorre superare e contro il quale ci si deve confrontare, che ho definito come modello baseline, assume semplicemente che tutte le donne si salveranno; applicando questa condizione elementare, si raggiunge un’accuratezza dell’insieme di passeggeri da classificare di poco superiore al 76%.
Questa competizione è un’ottima introduzione alla piattaforma Kaggle e richiede lo sviluppo di tutte le fasi di costruzione di un modello predittivo: analisi dei dati, preparazione e raffinamento dei dati, visualizzazione dei dati, costruzione del modello, validazione del modello e della sua accuratezza, comprensione della piattaforma Kaggle.

Nel mio notebook ho deciso di affrontare la sfida in Python costruendo un modello tramite la libreria XGBoost nota sia per essere alla base delle migliori implementazioni all’avanguardia del settore ma anche perché alla base dei modelli vincenti delle competizioni Kaggle. Tale libreria implementa il framework Gradient Boost in modalità estremamente scalabile, efficiente e portabile.
La mia implementazione, già completamente funzionante, è ancora in evoluzione è raggiungibile a questo indirizzo:
